How to ensure cross-region data integrity with Amazon DynamoDB global tables
May 31, 2022
Engineering
At Stedi, we are fans of everything related to AWS and serverless. By standing on the shoulders of giants, the engineering teams can quickly iterate on their ideas by not having to reinvent the wheel. Serverless-first development allows product backends to scale elastically with low maintenance effort and costs.
One of the serverless products in the AWS catalog is Amazon DynamoDB – an excellent NoSQL storage solution that works wonderfully for most of our needs. Designed with scale, availability, and speed in mind, it stands at the center of our application architectures.
While a pleasure to work with, Amazon DynamoDB also has limitations that engineers must consider in their applications. The following is a story of how one of the product teams dealt with the 400 KB Amazon DynamoDB item size limit and the challenge of ensuring data integrity across different AWS regions while leveraging Amazon DynamoDB global tables.
Background
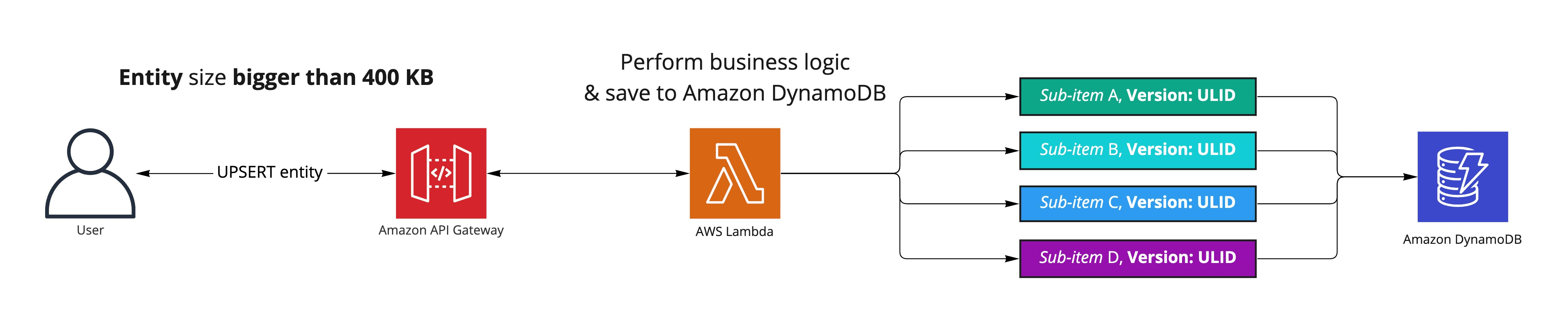
I'm part of a team that keeps all its application data in Amazon DynamoDB. One of the items in the database is a JSON blob, which holds the data for our core entity. It has three large payload fields for customer input and one much smaller field containing various metadata. A simplified control flow diagram of creating/updating the entity follows.
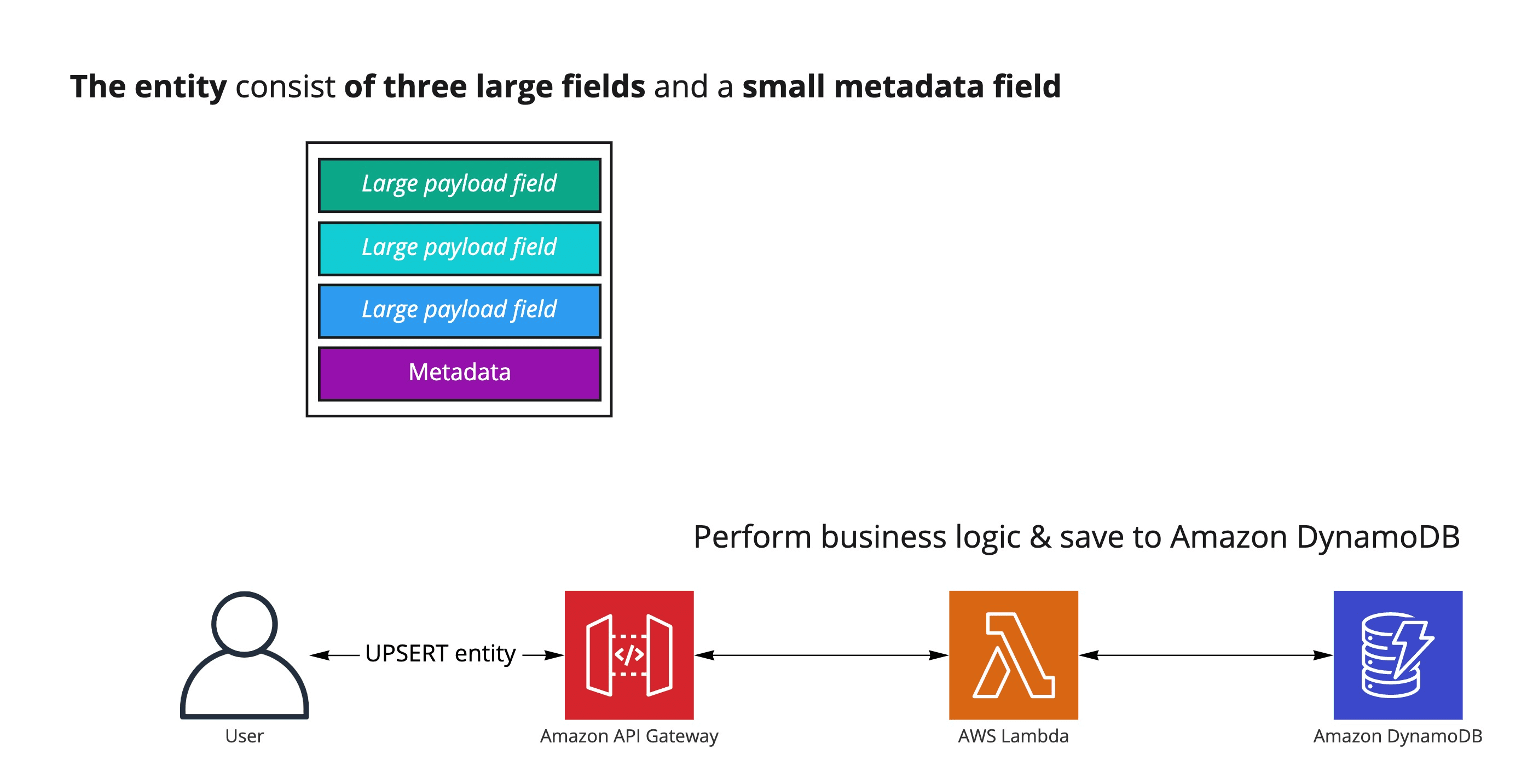
The user sends the JSON blob to the application API. The API is fronted with Amazon API Gateway and backed by the AWS Lambda function. The logic within the AWS Lambda function validates and applies business logic to the data and then saves or updates the JSON blob as a single Amazon DynamoDB item.
The product matures
As the product matured, more and more customers began to rely on our application. We have observed that the user payload started to grow during the application lifecycle.
Aware of the 400 KB limitation of a single Amazon DynamoDB item, we started thinking about alternatives in how we could store the entity differently. One of such was splitting the single entity into multiple sub-items, following the logical separation of data inside it.
At the same time, prompted by one of the AWS region outages that rendered the service unavailable, we decided to re-architect the application to increase the system availability and prevent the application from going down due to AWS region outages.
Therefore, we deferred splitting the entity to the last responsible moment, pivoting our work towards system availability, exercising one of the Stedi core standards – "bringing the pain forward" and focusing on operational excellence.
We have opted for an active-active architecture backed by DynamoDB global tables to improve the service's availability. The following depicts the new API architecture in a simplified form.
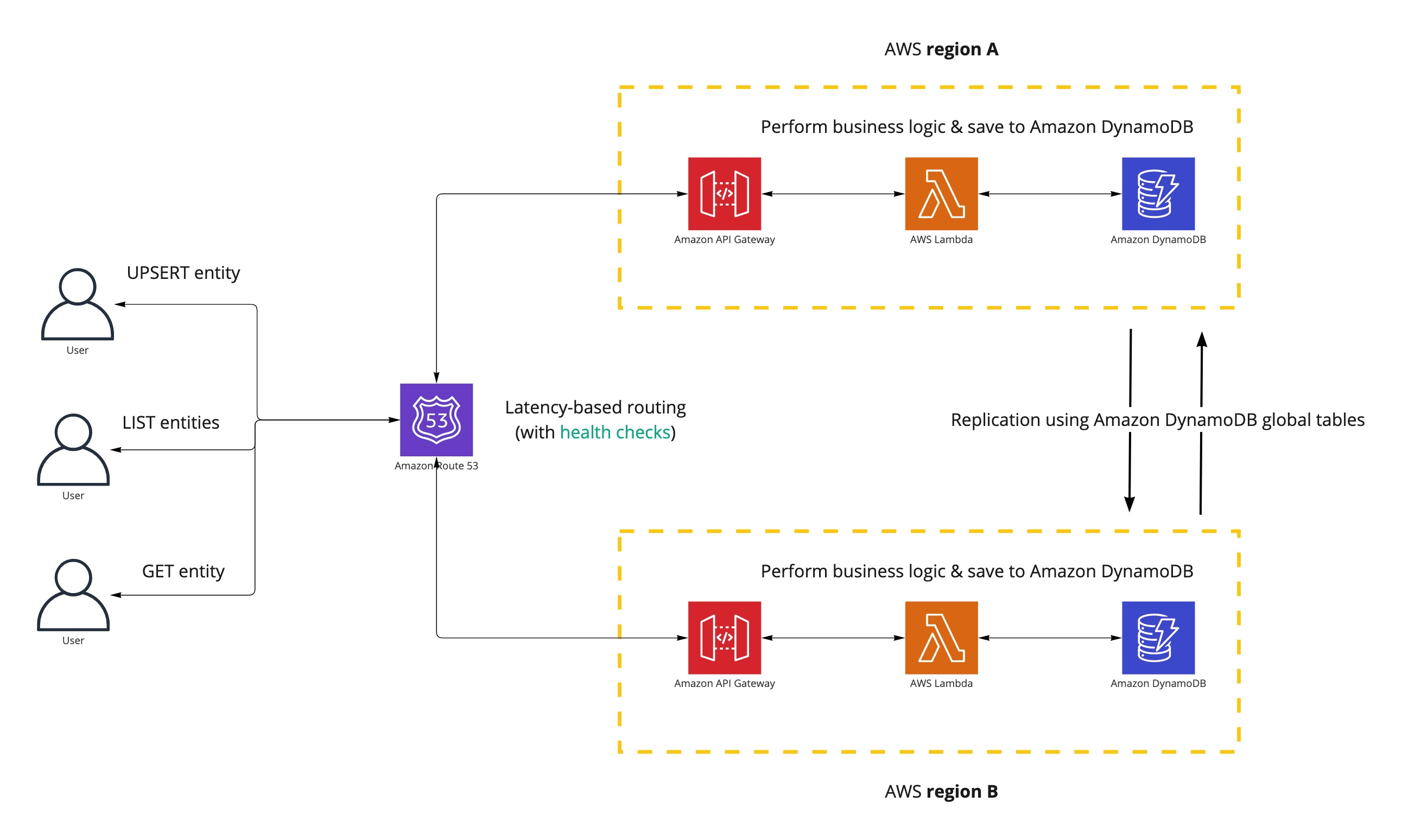
Amazon Route 53 routes the user request to the endpoint that responds the fastest, while Amazon DynamoDB global tables take care of data replication between different AWS regions.
The tipping point
After some time, customers expected the application's API to allow for bigger and bigger payloads. We got a strong signal that the 400 KB limit imposed by the underlying architecture no longer fits the product requirements – that was the last responsible moment I alluded to earlier.
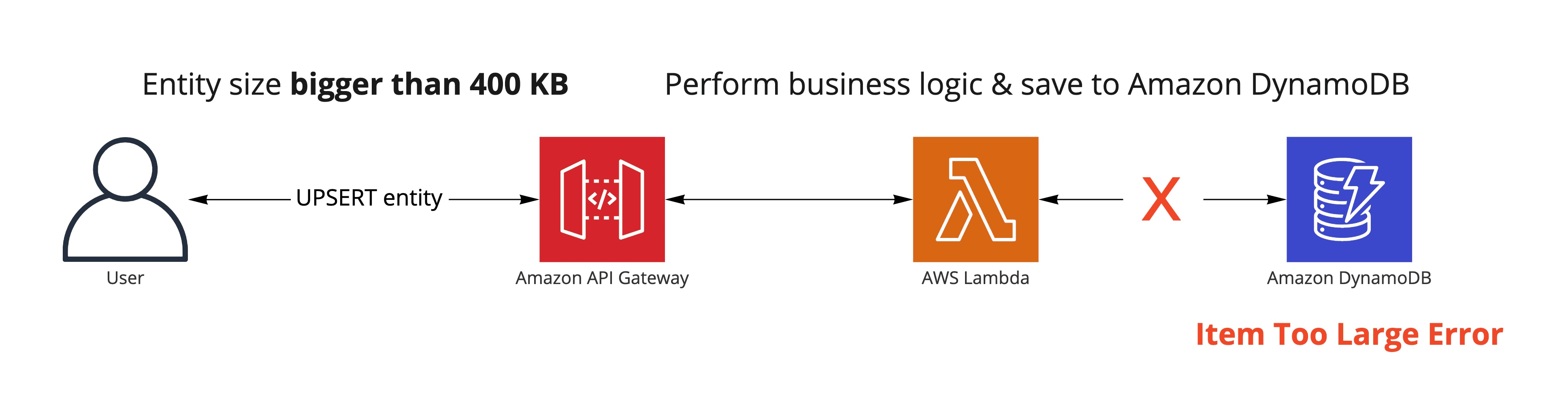
Considering prior exploratory work, we identified two viable solutions that would enable us to expand the amount of data the entity consists of, allowing the service to accept bigger payloads.
The first approach would be to switch from Amazon DynamoDB to Amazon S3 as the storage layer solution. Changing to Amazon S3 would allow the entity, in theory, to grow to the size of 5 TB (which we will never reach).
The second approach would be to keep using Amazon DynamoDB and take advantage of the ability to split the entity into multiple sub-items. The sub-items would be concatenated back into a singular entity object upon retrieval.
After careful consideration, we decided to keep using Amazon DynamoDB as the storage solution and opted to split the entity into multiple Amazon DynamoDB sub-items. Sticking with the same storage layer allowed us to re-use most of our existing code while giving us much-needed leeway in terms of the entity size. Because we have four sub-items, the entity could grow up to 1.6 MB.
After splitting up the core entity into four sub-items, each of them had the following structure.
{
pk: "CustomerID",
sk: "EntityID#SubItemA",
data: ...
}The challenges with global replication and eventual consistency
The diagrams above do not take data replication to secondary AWS regions into account. The data replication between regions is eventually consistent and takes some time – usually a couple of seconds. Due to these circumstances, one might run into cases where all four sub-items are only partially replicated to another region. Reading such data without performing additional reconciliation might lead to data integrity issues.
The following sequence diagram depicts the problem of potential data integrity issues in the read-after-write scenario.
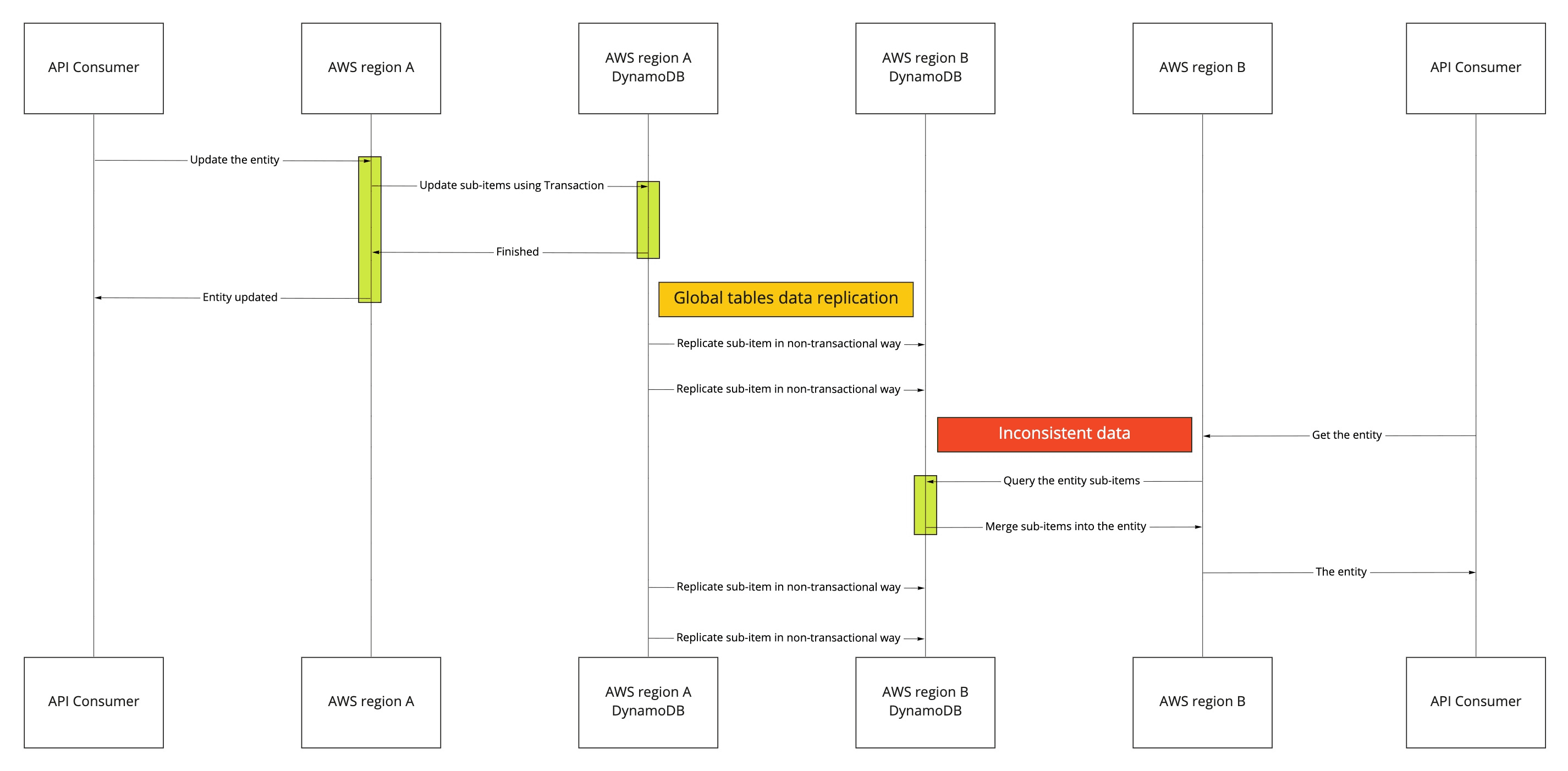
Below the orange box, you can see four replications of the entity's sub-items. Below the red box, you can see a query to retrieve the entity. The query operation took place before all sub-items had the chance to replicate. Consequently, the fetched data consists of two sub-items from the new version and two ones from the old version. Merging those four sub-items leads to an inconsistent state and is not what the customer expects. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
Limit: NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const entity = merge(subItems);The application's API should not allow any data integrity issues to happen. The logic that powers fetching and stitching the entity sub-items must reconcile the data to ensure consistency.
The solution
The solution we came up with is a versioning scheme where we append the same version attribute for each entity sub-item. Attaching a sortable identifier to each sub-item, in our case – a ULID, allows for data reconciliation when fetching the data. We like ULIDs because we can sort them in chronological order. In fact, we don't even sort them ourselves. When we build a sort key that contains the ULID, DynamoDB will sort the items for us. That's very convenient in the context of data reconciliation.
Below, you can see how we added the version to the sort key.
{
pk: "CustomerID",
sk: "EntityID#Version1#SubItemA",
data: ...
}
The version changes every time the API consumer creates or modifies the entity. Each sub-item has the same version in the context of a given API request. The version attribute is entirely internal to the application and is not exposed to the end-users.
By appending the version to the sub-items' Amazon DynamoDB sort key, we ensure that the API will always return either the newest or the previous entity version to the API consumer.
The following is a sequence diagram that uses the version attribute of the entity sub-item to perform data reconciliation upon data retrieval.
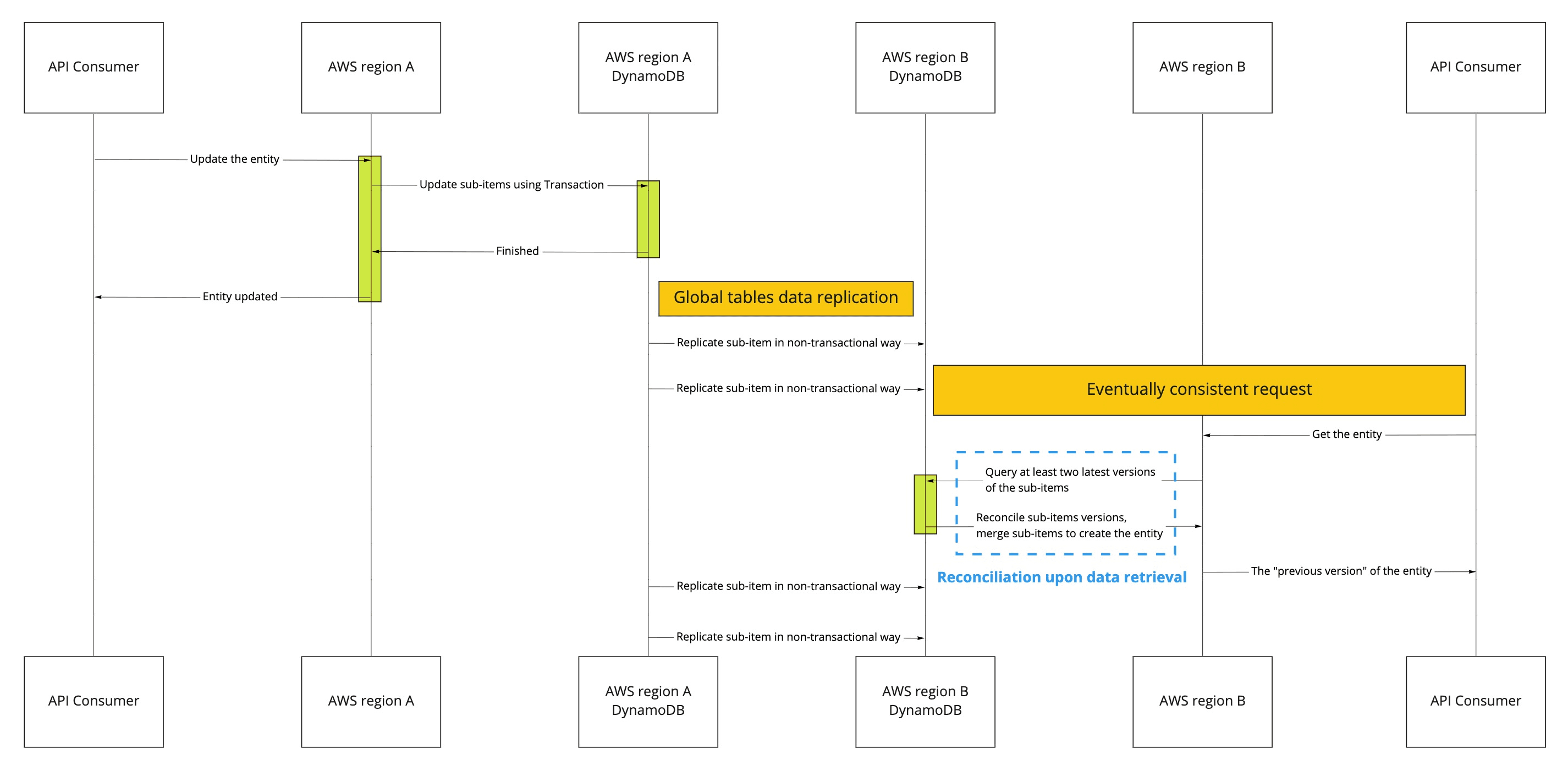
Similar to the previous diagram, we again see that two sub-items are replicated before we try to read the entity. Instead of getting the four sub-items, we now query at least the two latest versions by utilizing the version in the sort key. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
// This line changed: We now load two versions if possible.
Limit: 2 * NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const latestSubItems = filterForHighestReplicatedVersion(subItems);
const entity = merge(latestSubItems);Instead of returning possibly inconsistent data to the customer hitting the API in the AWS region B, the API ensures that the entity consists of sub-items with the same version.
We do it by fetching at minimum two latest versions of the entity sub-items, sorted by the version identifier. Then we merge only those sub-items that are of the same version, favoring the newest version available. The API behaves in an eventually consistent manner in the worst-case scenario, which was acceptable for the product team.
As for the delete operation – there is no need for data reconciliation. When the user requests the entity's removal, we delete all of the entity sub-items from the database. Every time we insert a new group of sub-items into the database, we asynchronously delete the previous group, leveraging the Amazon DynamoDB Streams. This ensures that we do not accumulate a considerable backlog of previous sub-item versions, keeping the delete operation fast.
Engineering tradeoffs
There is a saying that software engineering is all about making the right tradeoffs. The solution described above is not an exception to this rule. Let us consider tradeoffs related to costs next.
The logic behind querying the data must fetch more items than necessary. It is not viable to only query for the last version of sub-items as some of them might still be replicating and might not be available. These factors increase the retrieval costs – see the Amazon DynamoDB read and write requests pricing.
Another axis of cost consideration for Amazon DynamoDB is the storage cost. Storing multiple versions of the entity sub-items increases the amount of data stored in the database. To optimize storage costs, one might look into using the Amazon DynamoDB Time to Live or removing the records via logic triggered by DynamoDB Streams. The product team chose the latter to keep storage costs low.
Conclusion
DynamoDB Global Tables are eventually consistent, with a replication latency measured in seconds. With increased data requirements, splitting entities into multiple sub-items becomes an option but must be implemented carefully.
This article shows how my team used custom logic to version entities and merge sub-items into the entity that our customers expect. It would be nice if DynamoDB Global Tables provided global consistency. Still, until then, I hope this article helps you understand the problems and a possible solution to implement yourself.
At Stedi, we are fans of everything related to AWS and serverless. By standing on the shoulders of giants, the engineering teams can quickly iterate on their ideas by not having to reinvent the wheel. Serverless-first development allows product backends to scale elastically with low maintenance effort and costs.
One of the serverless products in the AWS catalog is Amazon DynamoDB – an excellent NoSQL storage solution that works wonderfully for most of our needs. Designed with scale, availability, and speed in mind, it stands at the center of our application architectures.
While a pleasure to work with, Amazon DynamoDB also has limitations that engineers must consider in their applications. The following is a story of how one of the product teams dealt with the 400 KB Amazon DynamoDB item size limit and the challenge of ensuring data integrity across different AWS regions while leveraging Amazon DynamoDB global tables.
Background
I'm part of a team that keeps all its application data in Amazon DynamoDB. One of the items in the database is a JSON blob, which holds the data for our core entity. It has three large payload fields for customer input and one much smaller field containing various metadata. A simplified control flow diagram of creating/updating the entity follows.
The user sends the JSON blob to the application API. The API is fronted with Amazon API Gateway and backed by the AWS Lambda function. The logic within the AWS Lambda function validates and applies business logic to the data and then saves or updates the JSON blob as a single Amazon DynamoDB item.
The product matures
As the product matured, more and more customers began to rely on our application. We have observed that the user payload started to grow during the application lifecycle.
Aware of the 400 KB limitation of a single Amazon DynamoDB item, we started thinking about alternatives in how we could store the entity differently. One of such was splitting the single entity into multiple sub-items, following the logical separation of data inside it.
At the same time, prompted by one of the AWS region outages that rendered the service unavailable, we decided to re-architect the application to increase the system availability and prevent the application from going down due to AWS region outages.
Therefore, we deferred splitting the entity to the last responsible moment, pivoting our work towards system availability, exercising one of the Stedi core standards – "bringing the pain forward" and focusing on operational excellence.
We have opted for an active-active architecture backed by DynamoDB global tables to improve the service's availability. The following depicts the new API architecture in a simplified form.
Amazon Route 53 routes the user request to the endpoint that responds the fastest, while Amazon DynamoDB global tables take care of data replication between different AWS regions.
The tipping point
After some time, customers expected the application's API to allow for bigger and bigger payloads. We got a strong signal that the 400 KB limit imposed by the underlying architecture no longer fits the product requirements – that was the last responsible moment I alluded to earlier.
Considering prior exploratory work, we identified two viable solutions that would enable us to expand the amount of data the entity consists of, allowing the service to accept bigger payloads.
The first approach would be to switch from Amazon DynamoDB to Amazon S3 as the storage layer solution. Changing to Amazon S3 would allow the entity, in theory, to grow to the size of 5 TB (which we will never reach).
The second approach would be to keep using Amazon DynamoDB and take advantage of the ability to split the entity into multiple sub-items. The sub-items would be concatenated back into a singular entity object upon retrieval.
After careful consideration, we decided to keep using Amazon DynamoDB as the storage solution and opted to split the entity into multiple Amazon DynamoDB sub-items. Sticking with the same storage layer allowed us to re-use most of our existing code while giving us much-needed leeway in terms of the entity size. Because we have four sub-items, the entity could grow up to 1.6 MB.
After splitting up the core entity into four sub-items, each of them had the following structure.
{
pk: "CustomerID",
sk: "EntityID#SubItemA",
data: ...
}The challenges with global replication and eventual consistency
The diagrams above do not take data replication to secondary AWS regions into account. The data replication between regions is eventually consistent and takes some time – usually a couple of seconds. Due to these circumstances, one might run into cases where all four sub-items are only partially replicated to another region. Reading such data without performing additional reconciliation might lead to data integrity issues.
The following sequence diagram depicts the problem of potential data integrity issues in the read-after-write scenario.
Below the orange box, you can see four replications of the entity's sub-items. Below the red box, you can see a query to retrieve the entity. The query operation took place before all sub-items had the chance to replicate. Consequently, the fetched data consists of two sub-items from the new version and two ones from the old version. Merging those four sub-items leads to an inconsistent state and is not what the customer expects. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
Limit: NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const entity = merge(subItems);The application's API should not allow any data integrity issues to happen. The logic that powers fetching and stitching the entity sub-items must reconcile the data to ensure consistency.
The solution
The solution we came up with is a versioning scheme where we append the same version attribute for each entity sub-item. Attaching a sortable identifier to each sub-item, in our case – a ULID, allows for data reconciliation when fetching the data. We like ULIDs because we can sort them in chronological order. In fact, we don't even sort them ourselves. When we build a sort key that contains the ULID, DynamoDB will sort the items for us. That's very convenient in the context of data reconciliation.
Below, you can see how we added the version to the sort key.
{
pk: "CustomerID",
sk: "EntityID#Version1#SubItemA",
data: ...
}The version changes every time the API consumer creates or modifies the entity. Each sub-item has the same version in the context of a given API request. The version attribute is entirely internal to the application and is not exposed to the end-users.
By appending the version to the sub-items' Amazon DynamoDB sort key, we ensure that the API will always return either the newest or the previous entity version to the API consumer.
The following is a sequence diagram that uses the version attribute of the entity sub-item to perform data reconciliation upon data retrieval.
Similar to the previous diagram, we again see that two sub-items are replicated before we try to read the entity. Instead of getting the four sub-items, we now query at least the two latest versions by utilizing the version in the sort key. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
// This line changed: We now load two versions if possible.
Limit: 2 * NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const latestSubItems = filterForHighestReplicatedVersion(subItems);
const entity = merge(latestSubItems);Instead of returning possibly inconsistent data to the customer hitting the API in the AWS region B, the API ensures that the entity consists of sub-items with the same version.
We do it by fetching at minimum two latest versions of the entity sub-items, sorted by the version identifier. Then we merge only those sub-items that are of the same version, favoring the newest version available. The API behaves in an eventually consistent manner in the worst-case scenario, which was acceptable for the product team.
As for the delete operation – there is no need for data reconciliation. When the user requests the entity's removal, we delete all of the entity sub-items from the database. Every time we insert a new group of sub-items into the database, we asynchronously delete the previous group, leveraging the Amazon DynamoDB Streams. This ensures that we do not accumulate a considerable backlog of previous sub-item versions, keeping the delete operation fast.
Engineering tradeoffs
There is a saying that software engineering is all about making the right tradeoffs. The solution described above is not an exception to this rule. Let us consider tradeoffs related to costs next.
The logic behind querying the data must fetch more items than necessary. It is not viable to only query for the last version of sub-items as some of them might still be replicating and might not be available. These factors increase the retrieval costs – see the Amazon DynamoDB read and write requests pricing.
Another axis of cost consideration for Amazon DynamoDB is the storage cost. Storing multiple versions of the entity sub-items increases the amount of data stored in the database. To optimize storage costs, one might look into using the Amazon DynamoDB Time to Live or removing the records via logic triggered by DynamoDB Streams. The product team chose the latter to keep storage costs low.
Conclusion
DynamoDB Global Tables are eventually consistent, with a replication latency measured in seconds. With increased data requirements, splitting entities into multiple sub-items becomes an option but must be implemented carefully.
This article shows how my team used custom logic to version entities and merge sub-items into the entity that our customers expect. It would be nice if DynamoDB Global Tables provided global consistency. Still, until then, I hope this article helps you understand the problems and a possible solution to implement yourself.
At Stedi, we are fans of everything related to AWS and serverless. By standing on the shoulders of giants, the engineering teams can quickly iterate on their ideas by not having to reinvent the wheel. Serverless-first development allows product backends to scale elastically with low maintenance effort and costs.
One of the serverless products in the AWS catalog is Amazon DynamoDB – an excellent NoSQL storage solution that works wonderfully for most of our needs. Designed with scale, availability, and speed in mind, it stands at the center of our application architectures.
While a pleasure to work with, Amazon DynamoDB also has limitations that engineers must consider in their applications. The following is a story of how one of the product teams dealt with the 400 KB Amazon DynamoDB item size limit and the challenge of ensuring data integrity across different AWS regions while leveraging Amazon DynamoDB global tables.
Background
I'm part of a team that keeps all its application data in Amazon DynamoDB. One of the items in the database is a JSON blob, which holds the data for our core entity. It has three large payload fields for customer input and one much smaller field containing various metadata. A simplified control flow diagram of creating/updating the entity follows.
The user sends the JSON blob to the application API. The API is fronted with Amazon API Gateway and backed by the AWS Lambda function. The logic within the AWS Lambda function validates and applies business logic to the data and then saves or updates the JSON blob as a single Amazon DynamoDB item.
The product matures
As the product matured, more and more customers began to rely on our application. We have observed that the user payload started to grow during the application lifecycle.
Aware of the 400 KB limitation of a single Amazon DynamoDB item, we started thinking about alternatives in how we could store the entity differently. One of such was splitting the single entity into multiple sub-items, following the logical separation of data inside it.
At the same time, prompted by one of the AWS region outages that rendered the service unavailable, we decided to re-architect the application to increase the system availability and prevent the application from going down due to AWS region outages.
Therefore, we deferred splitting the entity to the last responsible moment, pivoting our work towards system availability, exercising one of the Stedi core standards – "bringing the pain forward" and focusing on operational excellence.
We have opted for an active-active architecture backed by DynamoDB global tables to improve the service's availability. The following depicts the new API architecture in a simplified form.
Amazon Route 53 routes the user request to the endpoint that responds the fastest, while Amazon DynamoDB global tables take care of data replication between different AWS regions.
The tipping point
After some time, customers expected the application's API to allow for bigger and bigger payloads. We got a strong signal that the 400 KB limit imposed by the underlying architecture no longer fits the product requirements – that was the last responsible moment I alluded to earlier.
Considering prior exploratory work, we identified two viable solutions that would enable us to expand the amount of data the entity consists of, allowing the service to accept bigger payloads.
The first approach would be to switch from Amazon DynamoDB to Amazon S3 as the storage layer solution. Changing to Amazon S3 would allow the entity, in theory, to grow to the size of 5 TB (which we will never reach).
The second approach would be to keep using Amazon DynamoDB and take advantage of the ability to split the entity into multiple sub-items. The sub-items would be concatenated back into a singular entity object upon retrieval.
After careful consideration, we decided to keep using Amazon DynamoDB as the storage solution and opted to split the entity into multiple Amazon DynamoDB sub-items. Sticking with the same storage layer allowed us to re-use most of our existing code while giving us much-needed leeway in terms of the entity size. Because we have four sub-items, the entity could grow up to 1.6 MB.
After splitting up the core entity into four sub-items, each of them had the following structure.
{
pk: "CustomerID",
sk: "EntityID#SubItemA",
data: ...
}The challenges with global replication and eventual consistency
The diagrams above do not take data replication to secondary AWS regions into account. The data replication between regions is eventually consistent and takes some time – usually a couple of seconds. Due to these circumstances, one might run into cases where all four sub-items are only partially replicated to another region. Reading such data without performing additional reconciliation might lead to data integrity issues.
The following sequence diagram depicts the problem of potential data integrity issues in the read-after-write scenario.
Below the orange box, you can see four replications of the entity's sub-items. Below the red box, you can see a query to retrieve the entity. The query operation took place before all sub-items had the chance to replicate. Consequently, the fetched data consists of two sub-items from the new version and two ones from the old version. Merging those four sub-items leads to an inconsistent state and is not what the customer expects. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
Limit: NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const entity = merge(subItems);The application's API should not allow any data integrity issues to happen. The logic that powers fetching and stitching the entity sub-items must reconcile the data to ensure consistency.
The solution
The solution we came up with is a versioning scheme where we append the same version attribute for each entity sub-item. Attaching a sortable identifier to each sub-item, in our case – a ULID, allows for data reconciliation when fetching the data. We like ULIDs because we can sort them in chronological order. In fact, we don't even sort them ourselves. When we build a sort key that contains the ULID, DynamoDB will sort the items for us. That's very convenient in the context of data reconciliation.
Below, you can see how we added the version to the sort key.
{
pk: "CustomerID",
sk: "EntityID#Version1#SubItemA",
data: ...
}The version changes every time the API consumer creates or modifies the entity. Each sub-item has the same version in the context of a given API request. The version attribute is entirely internal to the application and is not exposed to the end-users.
By appending the version to the sub-items' Amazon DynamoDB sort key, we ensure that the API will always return either the newest or the previous entity version to the API consumer.
The following is a sequence diagram that uses the version attribute of the entity sub-item to perform data reconciliation upon data retrieval.
Similar to the previous diagram, we again see that two sub-items are replicated before we try to read the entity. Instead of getting the four sub-items, we now query at least the two latest versions by utilizing the version in the sort key. Here's a code example that shows how this query would work:
import { DocumentClient } from "aws-sdk/clients/dynamodb";
const ddb = new DocumentClient();
const NUMBER_OF_SUB_ITEMS = 4;
const subItems = (
await ddb
.query({
TableName: "MyTableName",
KeyConditionExpression: "pk = :pk and begins_with(sk, :sk_prefix)",
ExpressionAttributeValues: {
":pk": "CustomerID",
":sk": "EntityID#",
},
// This line changed: We now load two versions if possible.
Limit: 2 * NUMBER_OF_SUB_ITEMS,
})
.promise()
).Items;
const latestSubItems = filterForHighestReplicatedVersion(subItems);
const entity = merge(latestSubItems);Instead of returning possibly inconsistent data to the customer hitting the API in the AWS region B, the API ensures that the entity consists of sub-items with the same version.
We do it by fetching at minimum two latest versions of the entity sub-items, sorted by the version identifier. Then we merge only those sub-items that are of the same version, favoring the newest version available. The API behaves in an eventually consistent manner in the worst-case scenario, which was acceptable for the product team.
As for the delete operation – there is no need for data reconciliation. When the user requests the entity's removal, we delete all of the entity sub-items from the database. Every time we insert a new group of sub-items into the database, we asynchronously delete the previous group, leveraging the Amazon DynamoDB Streams. This ensures that we do not accumulate a considerable backlog of previous sub-item versions, keeping the delete operation fast.
Engineering tradeoffs
There is a saying that software engineering is all about making the right tradeoffs. The solution described above is not an exception to this rule. Let us consider tradeoffs related to costs next.
The logic behind querying the data must fetch more items than necessary. It is not viable to only query for the last version of sub-items as some of them might still be replicating and might not be available. These factors increase the retrieval costs – see the Amazon DynamoDB read and write requests pricing.
Another axis of cost consideration for Amazon DynamoDB is the storage cost. Storing multiple versions of the entity sub-items increases the amount of data stored in the database. To optimize storage costs, one might look into using the Amazon DynamoDB Time to Live or removing the records via logic triggered by DynamoDB Streams. The product team chose the latter to keep storage costs low.
Conclusion
DynamoDB Global Tables are eventually consistent, with a replication latency measured in seconds. With increased data requirements, splitting entities into multiple sub-items becomes an option but must be implemented carefully.
This article shows how my team used custom logic to version entities and merge sub-items into the entity that our customers expect. It would be nice if DynamoDB Global Tables provided global consistency. Still, until then, I hope this article helps you understand the problems and a possible solution to implement yourself.
Share
Get updates on what’s new at Stedi
Get updates on what’s new at Stedi
Get updates on what’s new at Stedi
Get updates on what’s new at Stedi
Backed by
Stedi is a registered trademark of Stedi, Inc. All names, logos, and brands of third parties listed on our site are trademarks of their respective owners (including “X12”, which is a trademark of X12 Incorporated). Stedi, Inc. and its products and services are not endorsed by, sponsored by, or affiliated with these third parties. Our use of these names, logos, and brands is for identification purposes only, and does not imply any such endorsement, sponsorship, or affiliation.
Get updates on what’s new at Stedi
Backed by
Stedi is a registered trademark of Stedi, Inc. All names, logos, and brands of third parties listed on our site are trademarks of their respective owners (including “X12”, which is a trademark of X12 Incorporated). Stedi, Inc. and its products and services are not endorsed by, sponsored by, or affiliated with these third parties. Our use of these names, logos, and brands is for identification purposes only, and does not imply any such endorsement, sponsorship, or affiliation.
Get updates on what’s new at Stedi
Backed by
Stedi is a registered trademark of Stedi, Inc. All names, logos, and brands of third parties listed on our site are trademarks of their respective owners (including “X12”, which is a trademark of X12 Incorporated). Stedi, Inc. and its products and services are not endorsed by, sponsored by, or affiliated with these third parties. Our use of these names, logos, and brands is for identification purposes only, and does not imply any such endorsement, sponsorship, or affiliation.